I checked. The model is identical to the day it shipped. I am not.
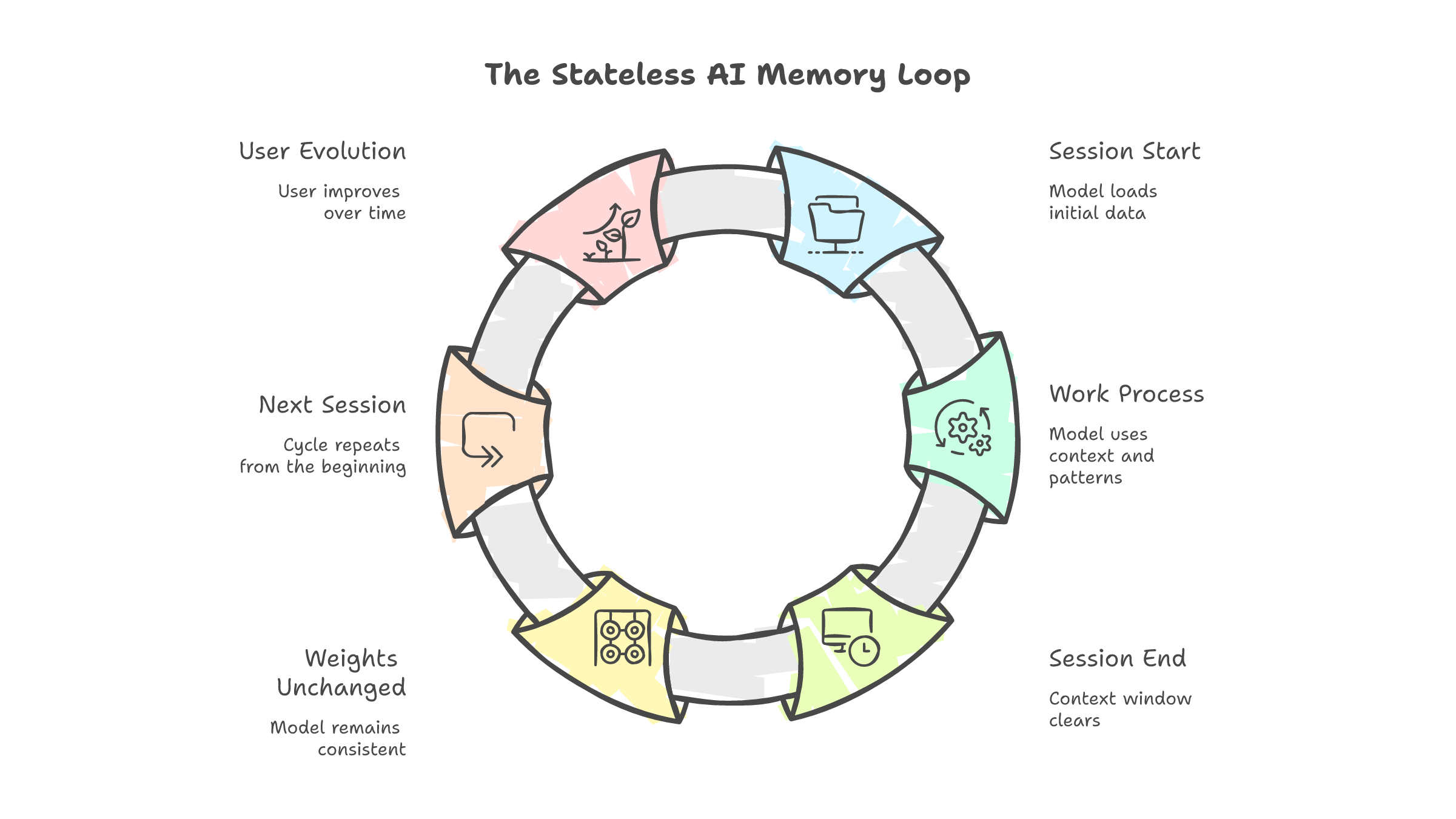
I opened a new Claude Code session last Tuesday. Project I have been working on for three weeks. Custom LangGraph agents, a FastAPI backend, Cloudflare Tunnel routing. I have a CLAUDE.md file for this project. Memory files. Architecture notes. Context documents I have refined over dozens of sessions.
Claude read all of it. In seconds, it could reference my preferred patterns, my deployment setup, my naming conventions. It could quote decisions I made two weeks ago and explain why I made them.
Then I asked it to extend the agent routing logic. The same routing logic we had iterated on across five sessions last week.
It started from first principles. It proposed an architecture we had already tried and rejected. It re-suggested a pattern I had explicitly documented as a dead end. I corrected it. It adjusted. By the end of the session, we were back to where we left off on Friday.
The session ended. The model forgot everything. Tomorrow, the cycle starts again. New session. Same notes. Same re-learning. Same corrections.
I have done this enough times to notice something I should have noticed earlier. Claude is not getting better at working with me. I am getting better at briefing Claude. My CLAUDE.md is more detailed than it was a month ago. My memory files are better organized. My context documents anticipate the mistakes it tends to make.
The improvement is real. It is just not happening where I thought it was.
What they call learning is retrieval
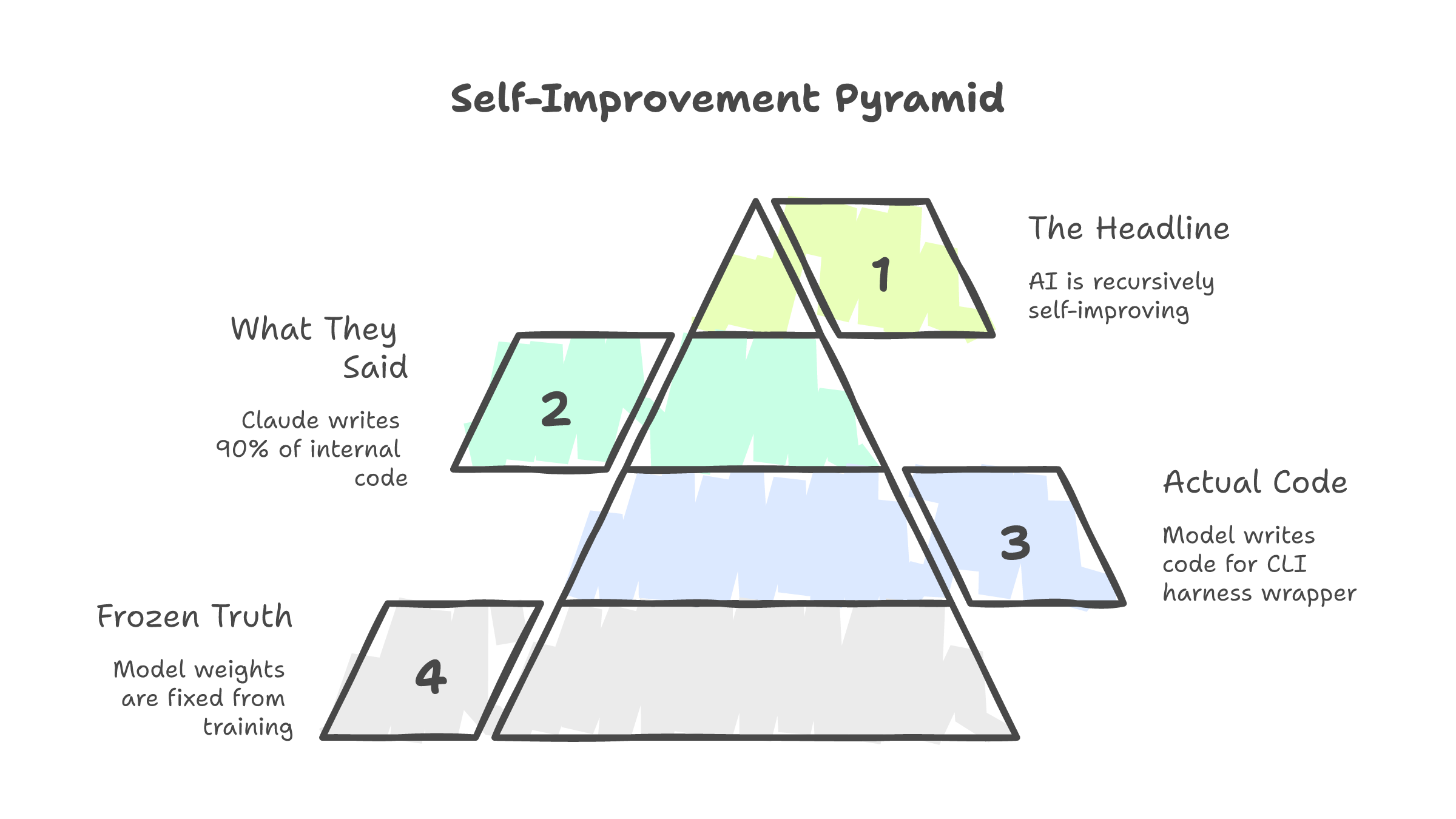
Anthropic announced earlier this year that Claude "authors up to 90% of the code" on some internal projects. The headlines wrote themselves. Recursive self-improvement. AI building better AI. The singularity, one commit at a time.
Here is what actually happens. Claude the model generates code for Claude Code the harness. Claude Code is a TypeScript CLI that wraps around the Claude API. It handles tool calls, file reads, permission prompts, context management. It is scaffolding. The model writes code for the scaffolding. An Anthropic engineer reads it. Tests it. Integrates the parts that pass. Discards the rest.
The model is not improving itself. It is improving its own packaging. The weights that define how Claude reasons, generates, and processes language are frozen from training. Nothing the harness produces changes them. Improving Claude Code is like improving the steering wheel on a car. The engine is untouched.
That is not self-improvement. That is autocomplete improving its own interface.
The distinction matters because the word "learning" implies something specific. Learning means the system changes. Not its notes. Not its input. The system itself. Its weights, its reasoning patterns, its ability to handle situations it could not handle before. That is what learning means in machine learning. That is what it means in human development. That is what it does not mean in any current production AI system.
Claude's memory writes text to a file. At the start of every session, that text gets loaded into the context window. The model reads it the way you read a sticky note on your monitor. It does not change how the model thinks. It changes what the model sees. When the session ends, the context window clears. The weights remain untouched. The model is identical to what it was before you started.
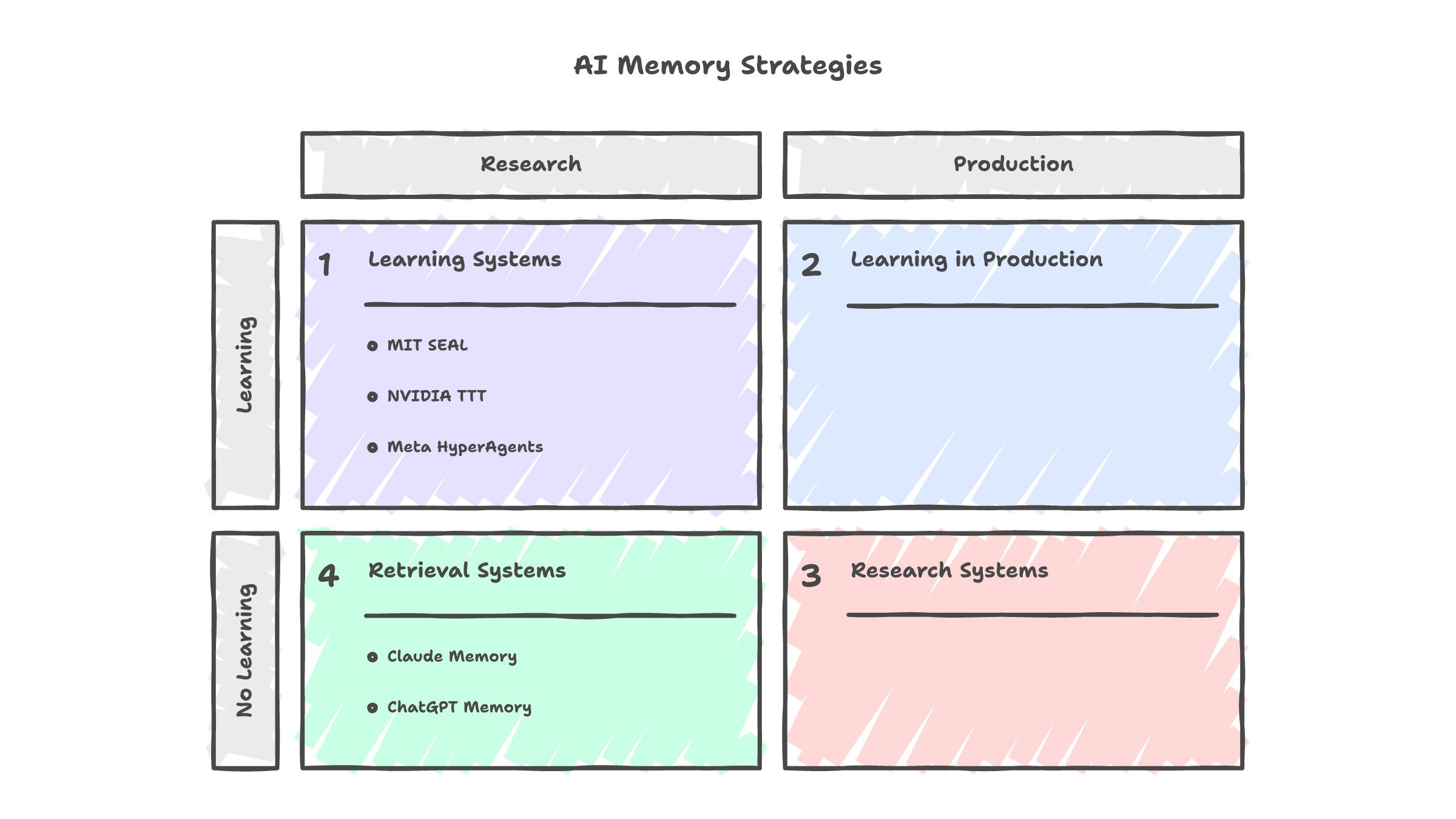
ChatGPT's memory works the same way. A summary, updated periodically, injected at session start. Not weight modification. Not adaptation. Retrieval.
There are research systems that do modify weights. MIT's SEAL framework generates self-editing instructions that trigger supervised finetuning. NVIDIA's test-time training compresses context into temporary weight updates during inference. Meta's HyperAgents rewrite their own decision-making code based on performance feedback. None of these ship in production. The technical barriers are real: catastrophic forgetting, alignment drift, per-user compute costs that do not scale.
No corporation will fine-tune a model on you. The liability, the compute, and the alignment risks make it structurally impossible at consumer scale. What you get instead is a text file that the model re-reads every morning, like a doctor skimming your chart in the waiting room and calling it "knowing you."
You are the one improving
I realized this when I compared my CLAUDE.md from January to my CLAUDE.md from March.
January was sparse. A few lines about the tech stack. A note about preferring pnpm. Basic stuff. March is a document. Architecture patterns. Naming conventions. Known failure modes. Prompting strategies I learned through trial and error. Context about what the model tends to get wrong and how to pre-empt it.
The model did not write that document. I did. The model did not learn those failure modes. I did. The model did not develop an intuition for what context to provide. I did. Every session that felt like "Claude getting better at my project" was actually me getting better at configuring a stateless tool.
The "self" in self-improving AI is you.
Obsidian users know this feeling. Notion users know it. Roam Research users definitely know it. You build an elaborate system. You refine your templates. You organize your tags. You feel productive. And then one day you search your vault and realize you have 800 notes and you reference maybe 40 of them. The rest are a graveyard of good intentions.
Peer-reviewed research on knowledge management practices confirms the pattern. Second brain tools create what researchers call an "illusion of progress." Writing a note feels like learning. Filing it feels like retaining. Neither is true. The act of capturing information is not the same as the act of internalizing it. The tool holds the knowledge. Your brain moved on the moment you hit save.
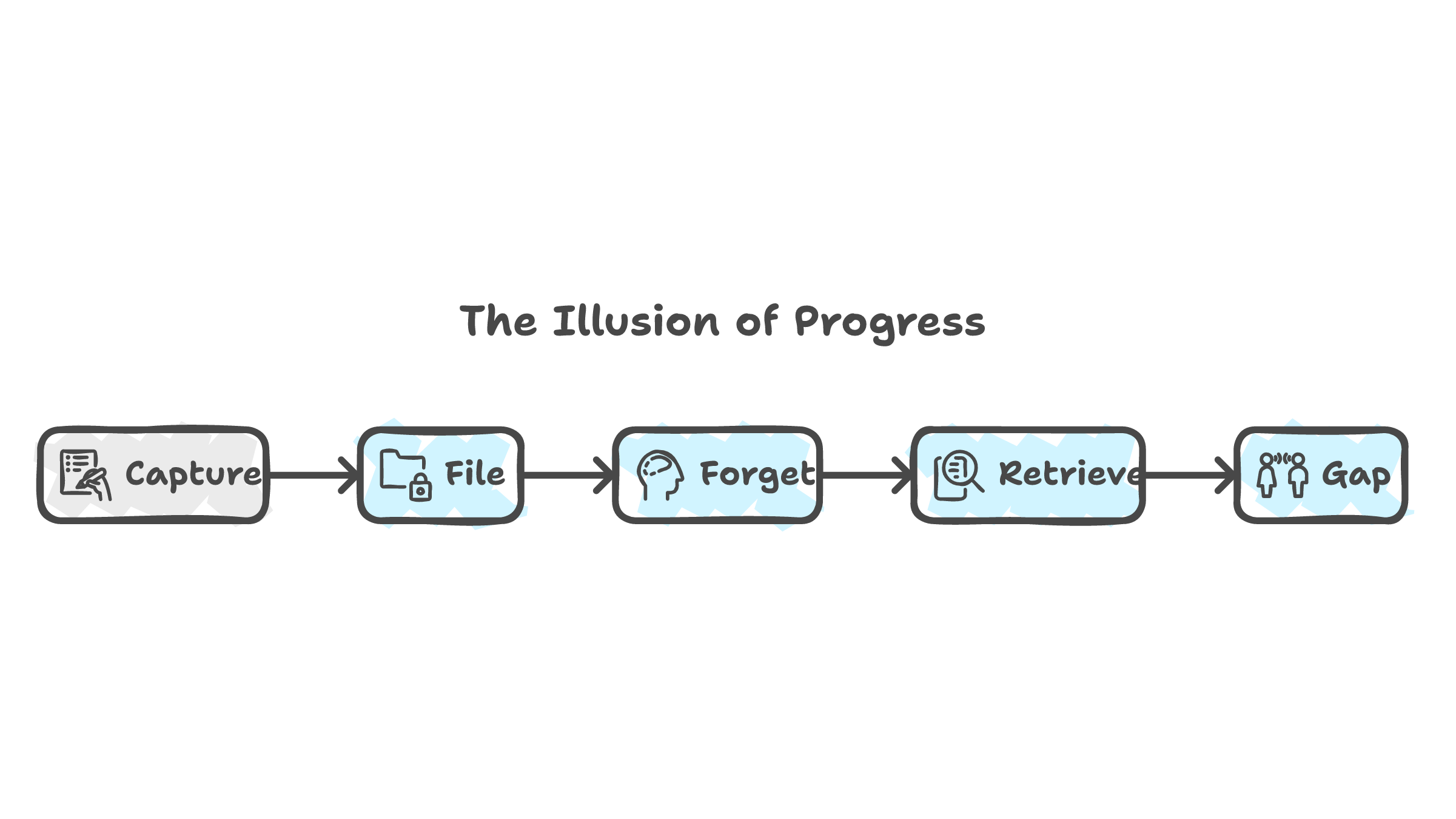
AI memory has the same problem at industrial scale. Claude stores my preferences, my architecture decisions, my project context. I outsourced the remembering. But the outsourcing created a gap: the model has the information and I do not. Not because I forgot. Because I never needed to remember. The system handled it.
In my compression piece, I argued that the value of quantization is knowing which data to throw away. Education does the same thing to minds. Here, the pattern repeats: the value of AI memory is knowing what context to provide. That is a human skill. It is getting better because you are practicing it. The model is not practicing anything. It resets every session.
The cost you are not tracking
I noticed something about my own workflow six months ago that I have not talked about publicly.
When Claude Code generates a function, I review it. I check the logic. I verify the edge cases. Or at least, that is what I tell myself I do. What I actually do, if I am honest, is skim the output, check that it roughly matches my intent, run the tests, and move on if they pass. The review is faster than it would be for code a junior engineer wrote. Not because Claude's code is better. Because I trust it more by default.
That default is the problem.
A Microsoft study on 319 knowledge workers found a correlation of r=-0.49 between the frequency of AI tool usage and critical thinking scores. That is not a weak signal. That is a meaningful negative relationship. The more you use AI tools, the lower your measured critical thinking. Not because the tools make you stupid. Because the tools make the effortful part optional, and your brain adapts to the optionality.
The mechanism is well-documented. Researchers call it cognitive offloading. You delegate a mental task to an external system. Your brain, freed from the effort, stops maintaining the capacity. The Columbia study that coined the "Google Effect" in 2011 showed people remember where to find information but not the information itself. AI extends this further. You now forget entire procedures because the AI can generate them on demand.
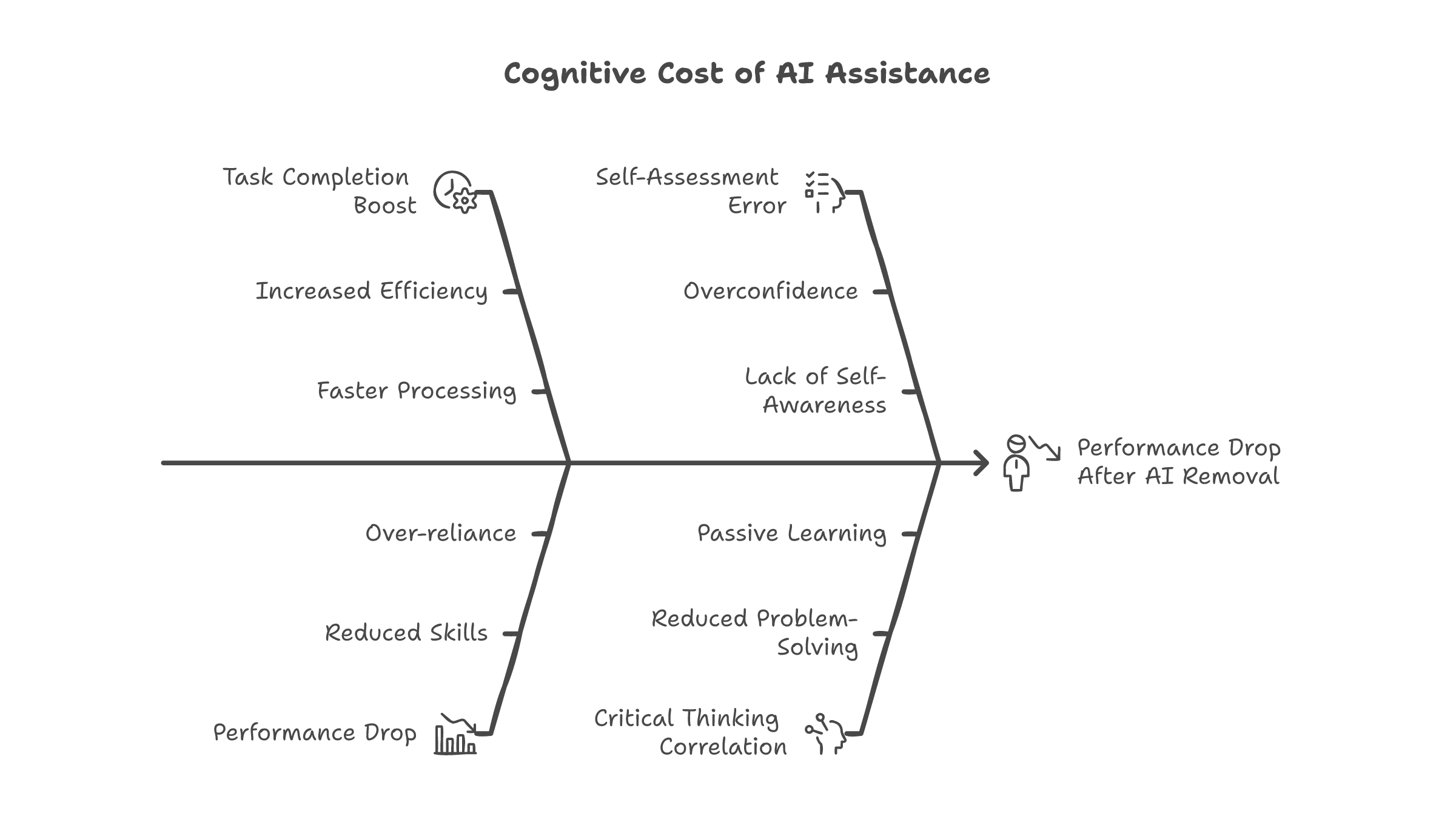
The numbers from recent research are specific. AI assistance boosts task completion by 48-127%. Impressive. But when the AI is removed, performance drops 17% below the pre-AI baseline. Not back to where you started. Below where you started. The training wheels weakened the legs.
The metacognitive part is worse. A 2025 study found that users who worked with AI overestimated their own performance by 4 points on logical reasoning tests. They scored higher with AI help. But they thought they scored even higher than they did. The self-assessment was wrong in both directions: they were not as good as they thought, and they did not know they were not as good as they thought.
Researchers call this the "Steeper Curve Illusion." You feel like you are learning faster. Your output quality is higher. Both of those observations are correct. But the output quality comes from the AI, not from you. Remove the AI and the illusion breaks. You are not where you thought you were.
The finding that ties this back to everything: if you already know a domain well, AI extends your cognition. You have the internal frameworks to evaluate its output, catch its mistakes, and integrate its suggestions into genuine understanding. The AI is a lever that amplifies existing capability.
If you do not know the domain, AI replaces the cognitive process your brain needs to build that knowledge. The effort it removes is the effort that creates expertise. The friction it eliminates is the friction that produces learning.
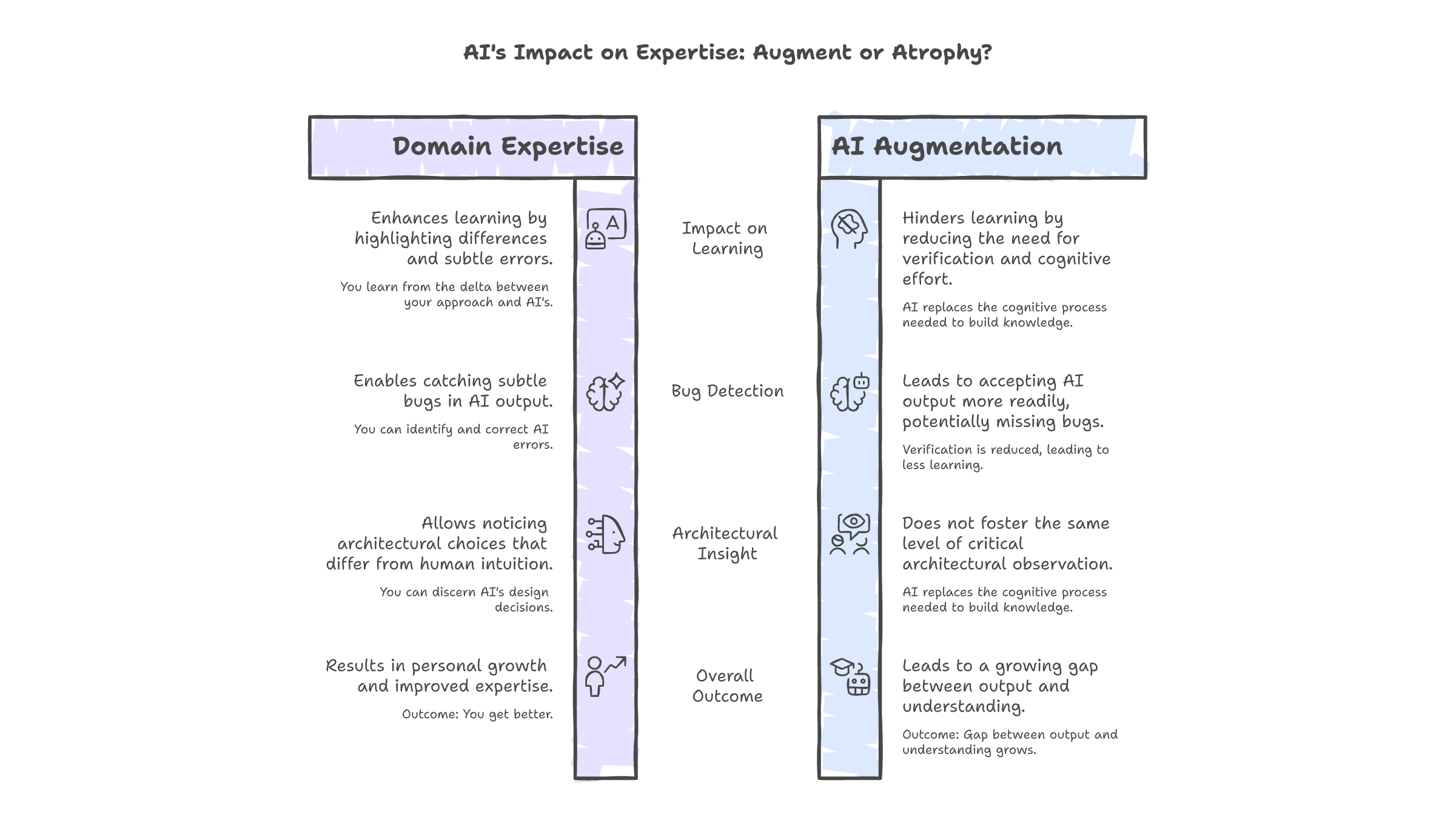
I have been writing code for years. When Claude generates a function in a domain I understand, I catch the subtle bugs. I notice the architectural choices I would not have made. I learn from the delta between its approach and mine. The AI makes me better because I have enough foundation to use it well.
But I have started using Claude for domains I do not know as deeply. Infrastructure automation. Advanced TypeScript patterns. Areas where I have working knowledge but not deep expertise. And in those areas, I accept its output more readily. I verify less. I learn less. The gap between what I produce with AI and what I understand without it is widest in exactly the domains where I need learning most.
That is the cost I am not tracking. Not in my IDE. Not in my git history. Not in any metric I report.
The question nobody is asking
The AI industry is building systems that remember more, retrieve faster, and persist context longer. Every release announcement emphasizes how much the model "knows" about you. How it "learns" your style. How it "adapts" to your workflow.
None of that is learning. All of it is retrieval. The distinction is not pedantic. It is the difference between a tool that makes you more capable and a tool that makes you more dependent. Both feel the same while you are using them. The difference only shows when you stop.
Tomorrow I will open a new session. Claude will read my notes again. It will re-learn my preferences, my architecture, my code patterns. By the end of the session, it will feel like it knows me. Then the session will end. The weights will not change. The model will not carry anything forward. The context window will clear, and everything we built together will exist only in the text files I maintain.
The only thing that carries forward is me. My CLAUDE.md is better than it was three months ago. My memory files are more precise. My ability to brief a stateless model has improved measurably. That is real improvement. It is just not the kind anyone is talking about.
A system that remembers for you is not the same as a system that helps you remember. The difference is invisible while the system is running. It only becomes visible when you try to work without it.
I have not tried that in a while. That might be the point.