We had the best model. It did not matter.
A client needed structured data extracted from scanned invoices and compliance documents. Hundreds of formats, inconsistent layouts, handwritten annotations in the margins. The kind of problem that frontier vision-language models are supposed to solve out of the box.
The intuitive approach was obvious: pass the document to Gemini 3 Pro, the largest vision-language model available at the time, and let it figure it out. One API call. Simple pipeline. Ship it by Friday.
The result: under 40% accuracy. Not on edge cases -- across the board. Fields transposed, tables misaligned, monetary amounts hallucinated. The model could describe what it saw in natural language. It could not reliably extract what we needed into structured fields.
The Accuracy Problem
That number forced us to rethink everything. Not which model to use, but how to use any model at all. The answer turned out to be an adaptive LangGraph pipeline using Qwen3 32B VL -- a significantly smaller, open-weight model -- that achieved over 90% accuracy on the same document set.
This is the story of how we got there and what it taught me about building production AI systems.
Why Single-Pass Extraction Fails
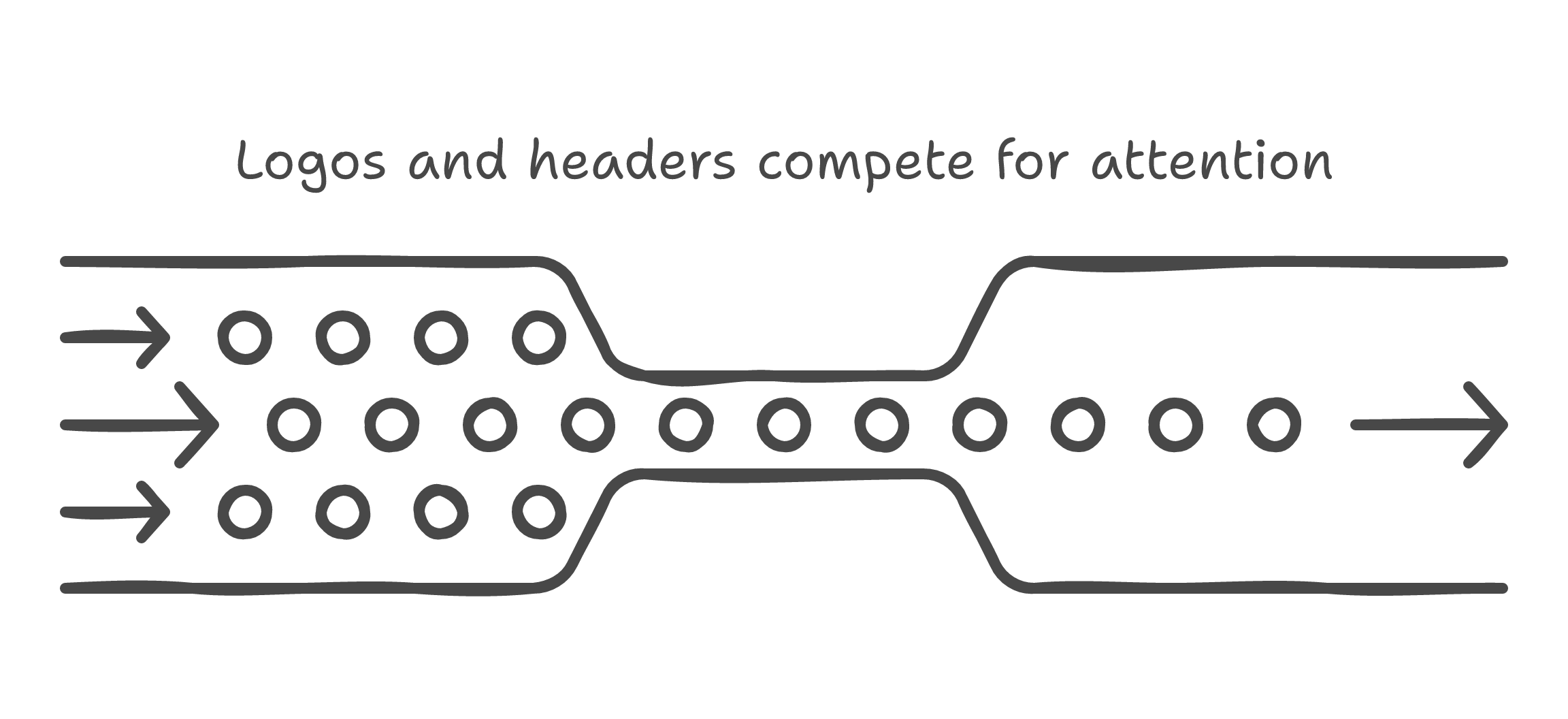
When you feed an entire document image to an LLM in one pass, the model receives roughly 15,000 tokens of visual information. Most of it is noise: headers, footers, watermarks, logos, decorative borders, irrelevant tables, page numbers, legal boilerplate.
The signal -- the actual invoice number, the line item amounts, the vendor name in 8pt font -- competes for attention with a company logo that occupies 20% of the page. This is not an intelligence problem. It is an attention allocation problem.
The model does not know what matters. It processes everything with roughly equal weight. When you ask it to extract twelve fields simultaneously from a full-page image, it is doing twelve different tasks at once with the same polluted context. Some fields get extracted correctly. Others get transposed, confused with visually adjacent data, or simply hallucinated.
Think of it this way: imagine handing someone a 50-page contract and asking them to extract the payment terms, the effective date, the governing jurisdiction, the penalty clauses, and the counterparty details -- all at once, in one read, with no ability to flip back. No human works this way. We scan, locate, focus, extract, and cross-check. We do it field by field, section by section. Why do we expect models to do it all in one pass?
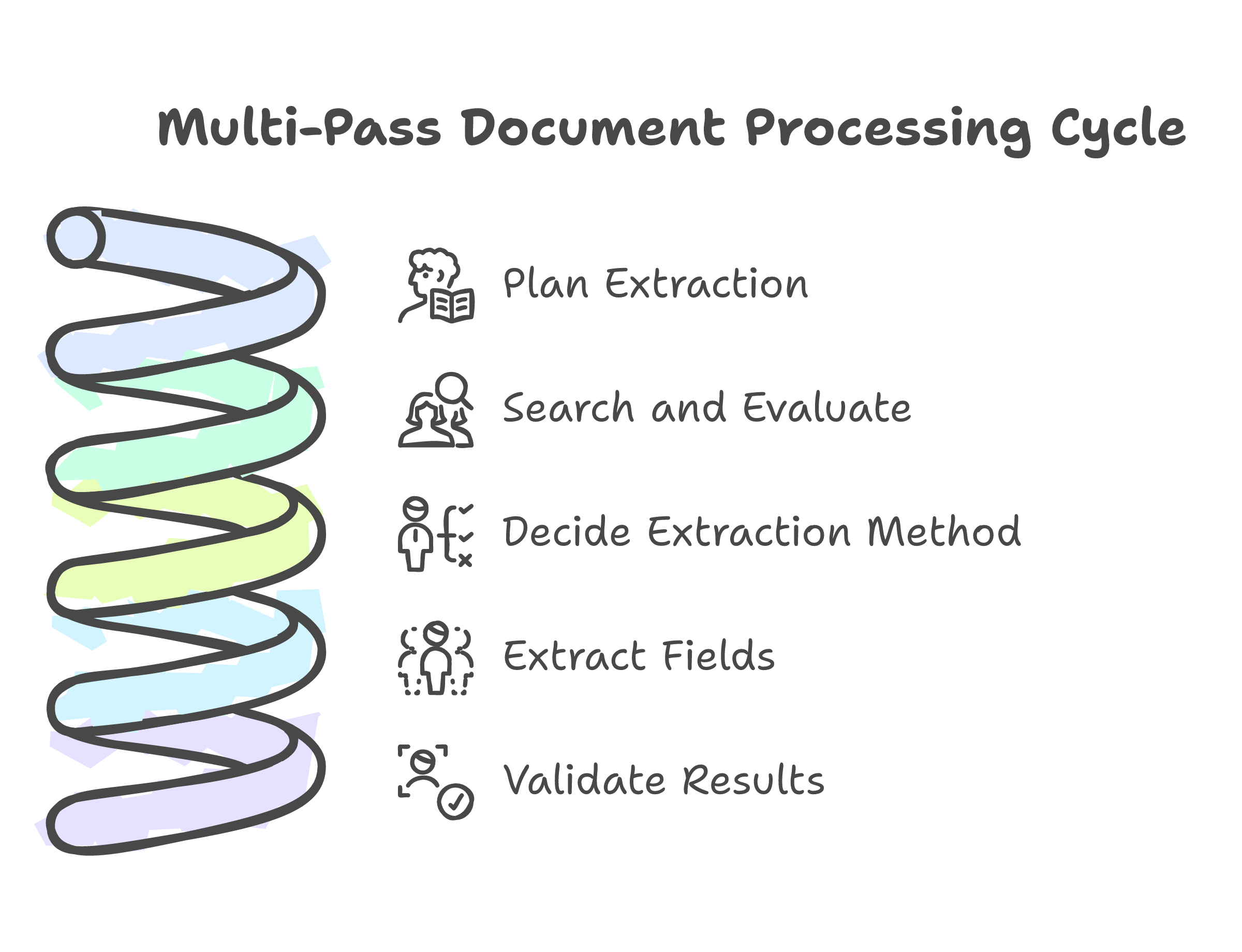
The analogy extends further. A human reading a complex document uses a multi-pass strategy: first understand what fields to look for, then search the document for relevant chunks, then evaluate whether each chunk actually contains useful data, then decide the best extraction method, and finally validate the results. Each step uses a different cognitive mode. Each step builds on the output of the previous one.
This is not a single inference. It is a directed graph.
The Insight: The Graph Is the Product
The turning point came when we stopped asking "which model extracts best?" and started asking "how does a skilled human actually read a document?"
A skilled document processor does something like this:
- Plans the extraction -- reads the schema, understands what fields to find and what types they should be
- Searches and evaluates -- scans the document for relevant sections, evaluates whether each section actually contains the target data (and loops back to search again if not)
- Decides the extraction method -- is this a text-heavy section that a language model can parse, or a scanned image that needs a vision-language model?
- Extracts and validates -- pulls the fields with focused attention, then cross-checks for consistency (and retries specific fields if confidence is low)
The Model Is a Component
Once we made this mental shift, the architecture designed itself. We did not need a bigger model. We needed a better graph -- one that gave a smaller model exactly the right context at exactly the right moment.
The Architecture: An Adaptive LangGraph Pipeline
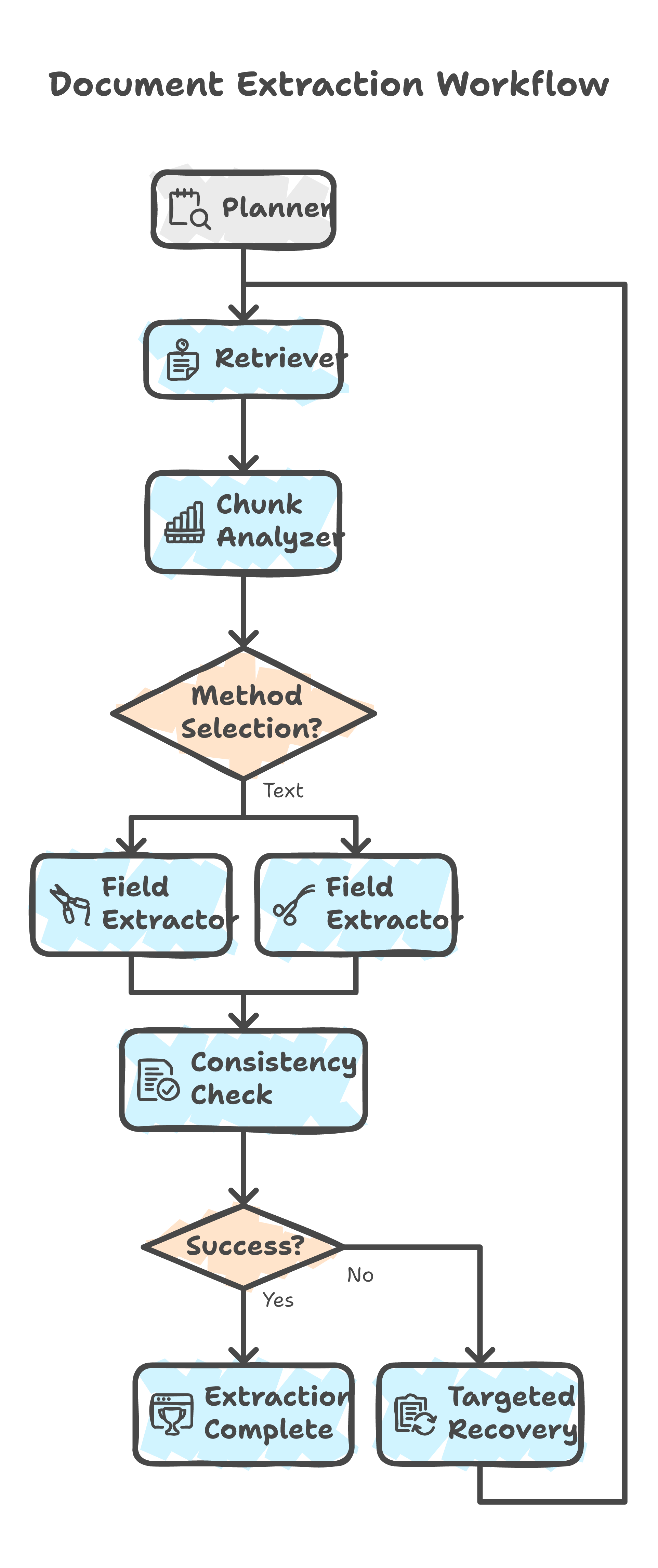
Here is the pipeline. Unlike a simple chain, this is an adaptive graph with conditional loops -- nodes that can route back to earlier stages based on what they find.
Node 1: Planner
The Planner receives the extraction schema and the document. Its job is narrow: understand what fields need to be extracted, what types they should be, and produce an extraction plan. It outputs a structured plan -- not extracted data.
This node can use a lightweight model because it is answering a planning question, not an extraction question. "What fields do we need and where might they be?" is a fundamentally easier task than "extract the invoice number, date, and vendor name from this image."
Nodes 2-3: Retriever + Evaluator (Conditional Loop)
The Retriever searches the document for chunks that are likely to contain the target fields. The Evaluator then scores each chunk: does this actually contain relevant data, or is it noise?
This is the first adaptive loop. If the Evaluator determines the retrieved chunks are insufficient -- low relevance scores, missing expected fields -- it routes back to the Retriever with refined search criteria. This retrieve-evaluate loop continues until the system has high-confidence chunks or exhausts its retry budget.
This loop is the critical step. It reduces the downstream token count from 15,000 to a few hundred per chunk. Instead of one massive context window full of noise, we now have focused, relevant windows.
Node 4: Chunk Analyzer
The Chunk Analyzer examines each retrieved chunk and decides the extraction method. Text-heavy chunks with clear structure get routed to standard text extraction. Chunks that are scanned images, contain handwriting, or have complex table layouts get routed to Qwen3 32B VL for vision-language extraction.
This selective VLM routing is key. Not every chunk needs a vision model. Sending clean, structured text through a VLM is wasteful. Sending a scanned table through a text-only model is futile. The Chunk Analyzer makes this routing decision per-chunk.
Node 5: Field Extractor (Qwen3 32B VL)
The core extraction node. It receives one focused chunk at a time -- a few hundred tokens of relevant context instead of 15,000 tokens of noise. For VLM-routed chunks, Qwen3 32B VL extracts specific fields with a defined schema. For text-routed chunks, a lighter model handles extraction.
Multiple focused calls, each with clean context, outperform one massive call with polluted context. This is the key insight: context quality beats model size.
Node 6: Validator (Recovery Loop)
The Validator receives all extracted fields and runs consistency checks. Do line items sum to the stated total? Does the date format match the locale? Is the invoice number format consistent with known vendor patterns?
It uses a confidence threshold. Anything below triggers a targeted recovery -- re-extracting that specific field from the same focused chunk, giving the model a second chance with identical clean context. After exhausting retries, low-confidence fields are flagged for human review rather than silently accepted.
The conditional edge back to the Field Extractor is what makes this a graph, not a chain. It enables targeted retry without reprocessing the entire document.
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
class ExtractionState(TypedDict):
document_pages: list[bytes]
extraction_plan: dict
chunks: Annotated[list[dict], operator.add]
evaluation_result: dict
extraction_method: dict
extracted_fields: Annotated[list[dict], operator.add]
validation_result: dict
retry_count: int
def plan(state: ExtractionState) -> dict:
"""Node 1: Analyze schema, produce extraction plan."""
schema = state.get("extraction_plan", {})
plan = planner_model.create_plan(state["document_pages"], schema)
return {"extraction_plan": plan}
def retrieve(state: ExtractionState) -> dict:
"""Node 2: Search document for relevant chunks."""
plan = state["extraction_plan"]
chunks = retriever.search(state["document_pages"], plan)
return {"chunks": chunks}
def evaluate(state: ExtractionState) -> dict:
"""Node 3: Score chunk relevance, decide if retrieval is sufficient."""
result = evaluator.score_chunks(state["chunks"], state["extraction_plan"])
return {"evaluation_result": result}
def should_re_retrieve(state: ExtractionState) -> str:
if state["evaluation_result"]["sufficient"]:
return "analyze"
if state["retry_count"] >= 2:
return "analyze"
return "retrieve"
def analyze_chunks(state: ExtractionState) -> dict:
"""Node 4: Decide extraction method per chunk (text vs VLM)."""
methods = {}
for chunk in state["chunks"]:
if chunk.get("is_scanned") or chunk.get("has_tables"):
methods[chunk["id"]] = "vlm"
else:
methods[chunk["id"]] = "text"
return {"extraction_method": methods}
def extract_fields(state: ExtractionState) -> dict:
"""Node 5: Qwen3 32B VL on VLM chunks, text model on text chunks."""
fields = []
for chunk in state["chunks"]:
method = state["extraction_method"].get(chunk["id"], "text")
if method == "vlm":
result = qwen3_32b_vl.extract(
chunk["content"],
expected_fields=state["extraction_plan"]["fields"]
)
else:
result = text_model.extract(
chunk["content"],
expected_fields=state["extraction_plan"]["fields"]
)
fields.append(result)
return {"extracted_fields": fields}
def validate(state: ExtractionState) -> dict:
"""Node 6: Consistency checks with confidence threshold."""
fields = state["extracted_fields"]
result = validator.check_consistency(fields)
return {"validation_result": result}
def should_retry(state: ExtractionState) -> str:
if state["validation_result"]["pass"]:
return "complete"
if state["retry_count"] >= 2:
return "complete" # Flag for human review
return "re_extract"
# Build the graph
graph = StateGraph(ExtractionState)
graph.add_node("plan", plan)
graph.add_node("retrieve", retrieve)
graph.add_node("evaluate", evaluate)
graph.add_node("analyze_chunks", analyze_chunks)
graph.add_node("extract_fields", extract_fields)
graph.add_node("validate", validate)
graph.set_entry_point("plan")
graph.add_edge("plan", "retrieve")
graph.add_edge("retrieve", "evaluate")
graph.add_conditional_edges(
"evaluate",
should_re_retrieve,
{"analyze": "analyze_chunks", "retrieve": "retrieve"}
)
graph.add_edge("analyze_chunks", "extract_fields")
graph.add_edge("extract_fields", "validate")
graph.add_conditional_edges(
"validate",
should_retry,
{"complete": END, "re_extract": "extract_fields"}
)
extraction_pipeline = graph.compile()
The Numbers: Smaller Model, Better Results, Lower Cost
| Metric | Gemini 3 Pro (single-pass) | Qwen3 32B VL (adaptive graph) |
|---|---|---|
| Model size | Frontier (undisclosed) | 32B parameters |
| Accuracy | Under 40% | Over 90% |
| Tokens per document | ~15,000 (one call) | ~2,000-3,000 (multiple focused calls) |
| Inference cost per doc | Higher (single large call) | Lower (multiple small calls) |
| Latency | Single round-trip | Multiple round-trips, parallelizable |
| Failure mode | Silent -- wrong data, high confidence | Explicit -- confidence scores flag uncertainty |
| Debugging | Black box | Node-level traceability |
The accuracy gap is the headline, but the cost and debuggability differences are what matter for production.
Multiple focused calls at a few hundred tokens each total roughly 2,000-3,000 tokens -- a significant reduction from the 15,000-token single pass. Fewer tokens means faster inference per call and lower cost per document. At scale (hundreds of invoices per batch), this adds up fast.
Failure Locality
This debuggability transformed our error resolution workflow. Instead of re-running the entire extraction and hoping for a different result, we could trace the failure to a specific node, inspect its input and output, and fix the root cause. Production support tickets went from "extraction is wrong" to "the Chunk Analyzer routed this page to text extraction but it was a scanned image."
The Trade-Offs Nobody Talks About
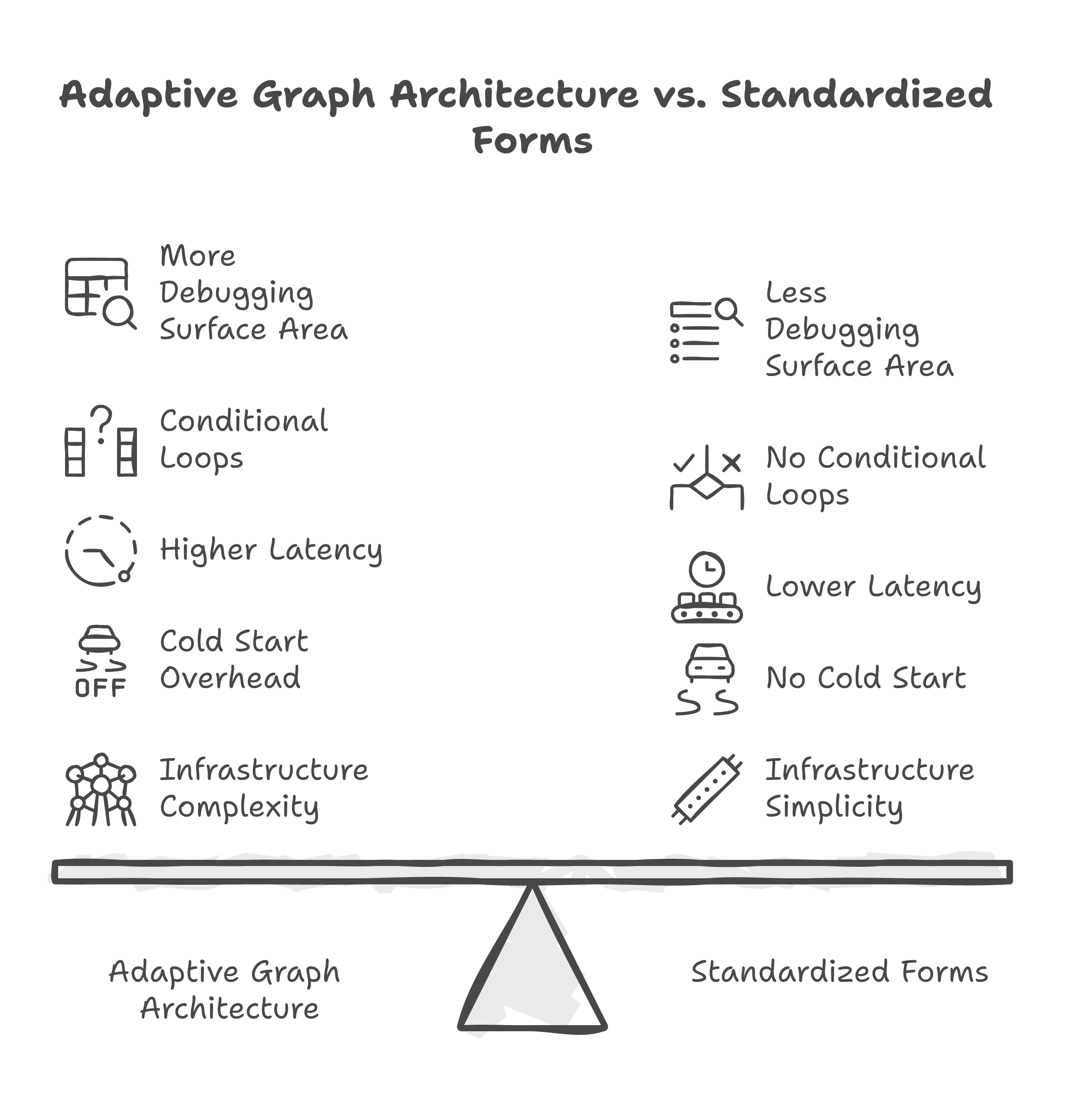
Let me be honest about what this architecture costs you.
Debugging Surface Area
A single API call has one failure mode: bad output. An adaptive graph has many more failure points. Six nodes that can error. Conditional loops that can cycle indefinitely without proper bounds. State transitions that can corrupt data. Output schemas that can be malformed. You need structured logging at every edge, not just at the final output.
We built a trace viewer that captures the full state object at every node boundary. Without it, debugging the graph would be harder than debugging the single-pass approach it replaced.
Latency
Sequential nodes add round-trips. The Planner must complete before the Retriever can start. Conditional loops add additional round-trips when chunks need re-retrieval or fields need re-extraction. For real-time use cases (user uploads a document and expects results in under a second), this matters. For batch processing -- our case, overnight extraction of hundreds of invoices -- it does not.
Know your latency budget before choosing the architecture. If you need sub-second responses, you might need to parallelize aggressively or accept a simpler pipeline with a more capable model.
Maintenance Burden
The graph is code. Code needs tests, documentation, and versioning. When the document format changes (new vendor, new invoice layout), you are updating node logic, not swapping a model. This is both the strength and the cost -- you have control, but you also have responsibility.
We maintain a test suite of representative documents across vendor templates. Every change to node logic runs against this suite before deployment. This is more infrastructure than a single API call requires. It is also why we catch regressions before they reach production.
When Single-Pass Is Fine
Know When to Keep It Simple
Not every problem needs an adaptive pipeline. A standardized form with predictable fields in predictable locations can be handled by a single well-prompted call to a capable model. The graph is for the messy real world where documents come in hundreds of formats and "close enough" is not acceptable.
The Broader Lesson: Architect the Workflow
Every production AI system is a workflow, not a single inference call. The question is whether you design that workflow explicitly -- as a graph with defined nodes, edges, and state -- or leave it implicit, stuffed into one massive prompt and hoping the model figures it out.
The AI industry's fixation on model benchmarks obscures the real engineering question: given a fixed accuracy requirement, what is the simplest graph that meets it? Sometimes the answer is one node with a frontier model. Often, the answer is multiple nodes with smaller, cheaper models doing focused work.
This is not a new insight. Software engineering has always been about decomposing complex problems into manageable components with well-defined interfaces. The only thing that changed is that one of those components is now a language model. The engineering principles are the same.
The model is a component. The graph is the product. Design accordingly.
The next time someone tells you they need a bigger model, ask them if they have tried a better graph.