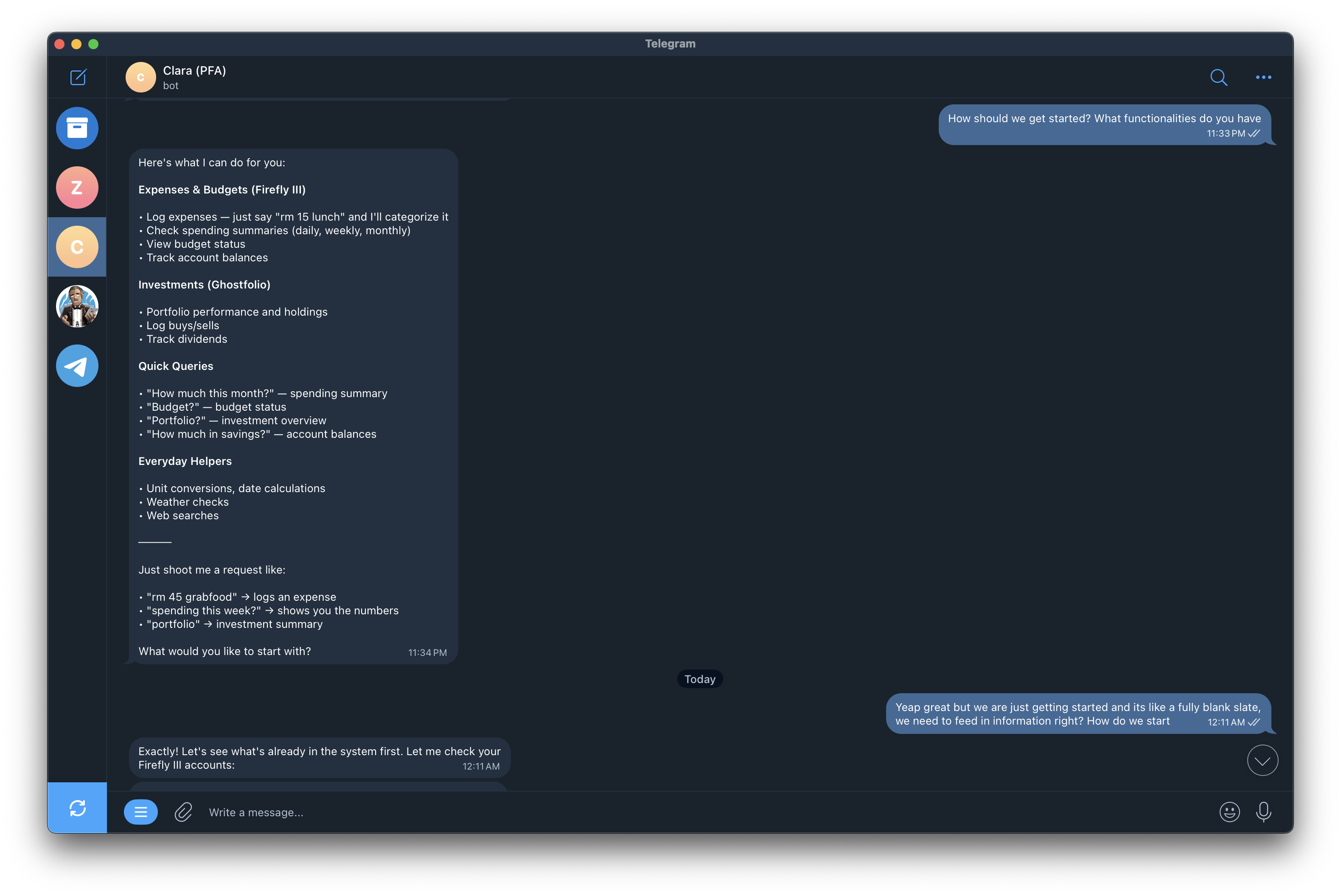
Last Tuesday at midnight, I asked my Telegram bot to set up three budget categories in Firefly III. Food: RM 3,000. Transport: RM 200. Rent: RM 1,200.
She created the categories in seconds. Then she tried to POST the budget amounts. Got an error. And instead of diagnosing the problem or trying another approach, she just... stopped.
"The API has an issue with nginx blocking POST requests to the limits endpoint," she told me. Then she listed three options and asked what I wanted to do.
The actual problem? A permission issue on the API call. Not nginx. She hallucinated a plausible-sounding root cause, presented it with confidence, and handed the problem back to me. I had to do the thinking for her.
Worse than being stuck
The thing is, ten minutes earlier she was flawless. "rm 45 grabfood" logged RM 45 under Food. "How much this month?" pulled a clean spending summary. "Portfolio?" showed my Ghostfolio holdings. No hesitation, no errors. An open model running on budget infrastructure, doing exactly what I built her to do.
Two tasks. One simple, one slightly complex. The gap between them is the thing I keep running into -- and the thing nobody in the OpenClaw discourse wants to talk about.
The real question
A genius does not need instructions

Here is how I think about it.
Give a senior engineer a vague brief and they will figure it out. They will read the docs, try alternatives when something breaks, make judgment calls about what to escalate and what to just fix. You can hand them autonomy because they have the reasoning capacity to use it.
Give an intern the same vague brief and they will get the straightforward parts right. Then they will get stuck. Not because they are bad at their job. Because the task exceeded what they can reason through on their own, and nobody gave them a checklist for the hard parts.
The SOP principle
OpenClaw, the biggest AI agent story of 2026, runs on this exact tradeoff. Peter Steinberger built it on open models -- Kimi K2.5 being the most popular, though it supports others. Running on a Raspberry Pi. It went viral. Millions of installs. OpenAI hired him for it.
And for the things it does -- managing your calendar, sending messages, looking up files, running simple automations -- it is genuinely good. These are tasks with clear intent and predictable tool calls. The model does not need to be a genius. It just needs to follow instructions.
But OpenClaw's architecture is a generalized workflow. There is no task-specific reasoning pipeline. No domain-aware error recovery. No multi-step verification loop. The entire system rests on one bet: the model behind it is smart enough to figure out whatever you throw at it.
When that model is Claude Opus or GPT-5, the bet pays off more often. When it is an open model, you start hitting ceilings. Not on the easy tasks. On the weird ones. The ones that require chaining three API calls where the second depends on interpreting the first. The ones where the error message is not in the training data.
Where Clara breaks
My bot Clara connects to two systems: Firefly III for expense tracking and budgets, Ghostfolio for investments. She runs on Telegram.
The routine stuff works without issues:
- I say "rm 15 lunch" and she logs RM 15 under Food
- I ask "spending this week?" and she pulls the numbers
- I say "portfolio?" and she shows my holdings
These are pattern-matching tasks. Clear input, one API call, predictable response. An open model handles them like a human handles tying their shoes.
The budget setup was different. It required two sequential API operations -- create categories, then POST limits through a separate endpoint. Clara nailed step one. Step two failed. And this is where the gap showed up.
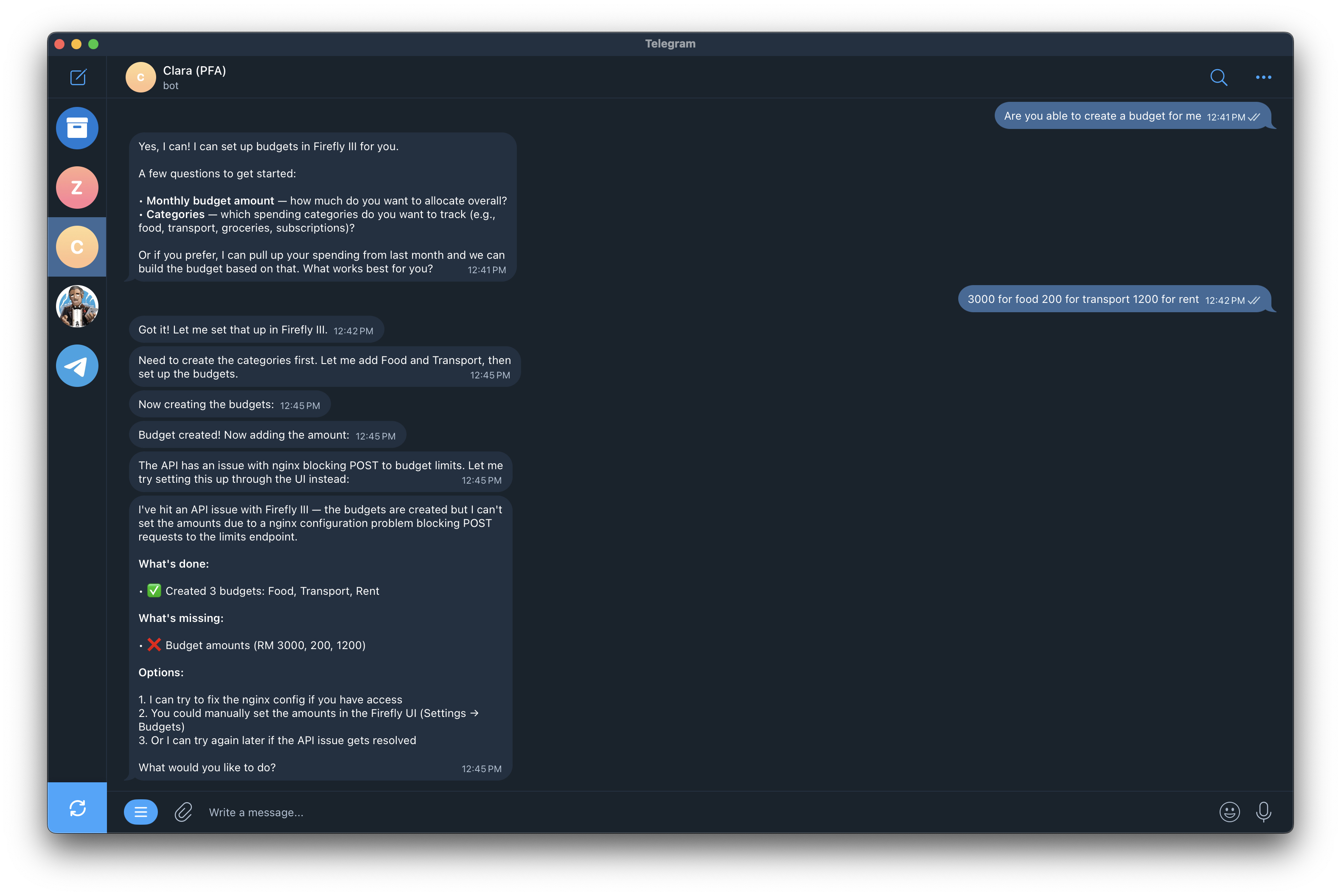
She told me the problem was nginx blocking POST requests. It was not. The actual issue was an API permission error. She hallucinated a confident, technical-sounding explanation that pointed me in the wrong direction entirely.
A stronger model might have checked the actual error response, tried with different credentials, or at minimum told me "I am not sure what went wrong" instead of fabricating a diagnosis. Clara gave me three generic recovery options built on a wrong premise. Polite. Confident. Actively misleading.
This is not a complaint
Benchmarks miss the interesting part
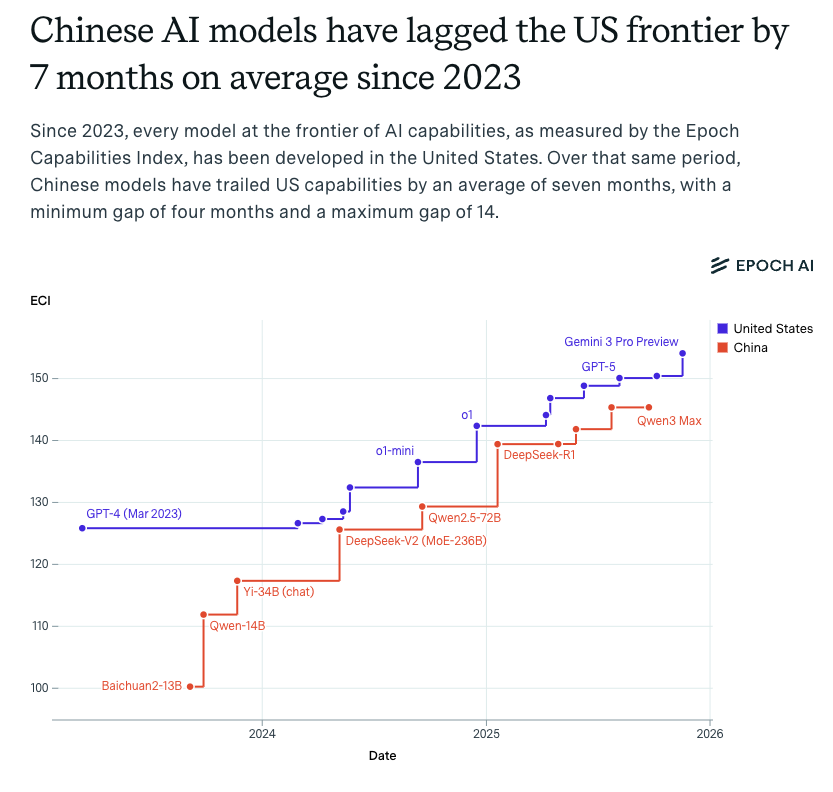
Epoch AI says open-weight models trail proprietary ones by about three months on average. And on benchmarks, that is probably true. DeepSeek V3.2 matches GPT-5.2 on most standardized tests. Qwen3-235B is competitive with anything.
But benchmarks measure average capability across defined tasks. They measure shoe-tying.
The three-month gap
They do not measure the model's ability to reason through a three-step recovery path it has never seen in training. That is where the gap feels a lot wider than three months.
Palo Alto Networks flagged AI agents as "2026's biggest insider threat" -- and OpenClaw, with its full system access and millions of installs, is the poster child for that warning. The security angle gets the headlines. But the part that concerns me more is the reasoning angle: an agent with full system access and limited ability to reason about consequences is a specific kind of risk that benchmarks do not capture.
Confident and wrong at scale
If you cannot get the genius, build a better guidebook
At Infomina AI, we run multiple LangGraph agents in production. Some use Claude. Some use open models. The choice is never about which model is cheaper.
It is about this: can this model handle autonomy on this task, or does it need a guidebook?
The architecture tradeoff
A genius solves problems you did not anticipate. You can give them a goal and they will figure out the path. An intern needs you to write the path down. Step one: try this endpoint. Step two: if it fails with a 4xx, try this alternative. Step three: if both fail, escalate with these details.
That is what good agent architecture does for open models. It is the SOP that compensates for the reasoning the model cannot do on its own.
For agents with well-defined tool schemas and predictable workflows -- data fetching, report generation, structured queries -- open models work fine because the guidebook is simple. The task is predictable enough that you can write down every path.
For agents that need to reason through novel situations -- deciding which pipeline to run, judging whether an extraction is complete, recovering from an error nobody anticipated -- you either need a smarter model or a much more detailed guidebook. And at some point, the guidebook for every possible edge case becomes impossible to write. That is when you need the genius.
I know this because I tried the obvious fix. I wrote Clara increasingly detailed instructions. Tool definitions with explicit parameters. Error handling rules for every API response code I could anticipate. Fallback paths when the primary endpoint failed. She got better. The ceiling moved higher.
But it did not disappear. The budget failure happened after all those improvements. I had already written her a detailed skill file covering Firefly III operations. She still hallucinated a diagnosis when she hit something the skill file did not cover. You cannot SOP your way out of a reasoning gap. At some point the model has to actually think, and no markdown file of instructions substitutes for that.
The SOP has a ceiling too
The real question for open models
The quiet part about Steinberger joining OpenAI
Everyone frames the hire as validation for open-source AI agents. It is.
But flip it around. OpenAI acquired the best general-agent architect in the world. Why? Because general agents need smarter models to handle the hard tasks. OpenClaw on Kimi 2.5 manages your calendar. OpenClaw on whatever OpenAI ships next might manage your company.
The model does not matter for simple tasks. For simple tasks, almost anything works.
For the hard stuff -- the reasoning, the recovery, the judgment calls at 2am when nobody is watching -- the model is everything. Open source handles the chores. It does not yet handle the thinking.
I still build with open models. Clara still runs on one. I just know where her ceiling is. And when she hits it, I do not blame her. I blame myself for not writing a better guidebook -- or for asking her to do something that no guidebook could cover.
That honesty about your model's limits might be the most useful thing I have learned building AI systems. Most people figure it out the hard way, after deploying an agent that confidently does the wrong thing on a task just slightly harder than the ones they tested.