A client handed us a 47-page regulatory compliance report and asked a simple question: "Does this document say we need to upgrade our KYC process by Q3?"
Our RAG system chunked the document, embedded it, retrieved the top-5 most relevant chunks, and confidently responded: "Yes, the document requires a KYC process upgrade by Q3 2025."
There was just one problem. The answer was wrong. The document mentioned KYC upgrades as a recommendation, not a requirement, and the deadline was Q3 2026, not 2025. The RAG system had retrieved a chunk that contained the right keywords but missed the conditional language and got the date wrong because the relevant date appeared in a different section than the KYC mention.
The Wrong Answer Problem
That failure led us to build what I call dual-mode document intelligence -- a system that combines passive RAG for simple lookups with agentic RAG for complex reasoning, plus a vision-language model pipeline for documents that are not machine-readable at all. Here is the architecture and the reasoning behind every major decision.
Why Basic RAG Fails for Enterprise Documents
Let me be specific about the failure modes, because "RAG does not work" is not a useful diagnosis.
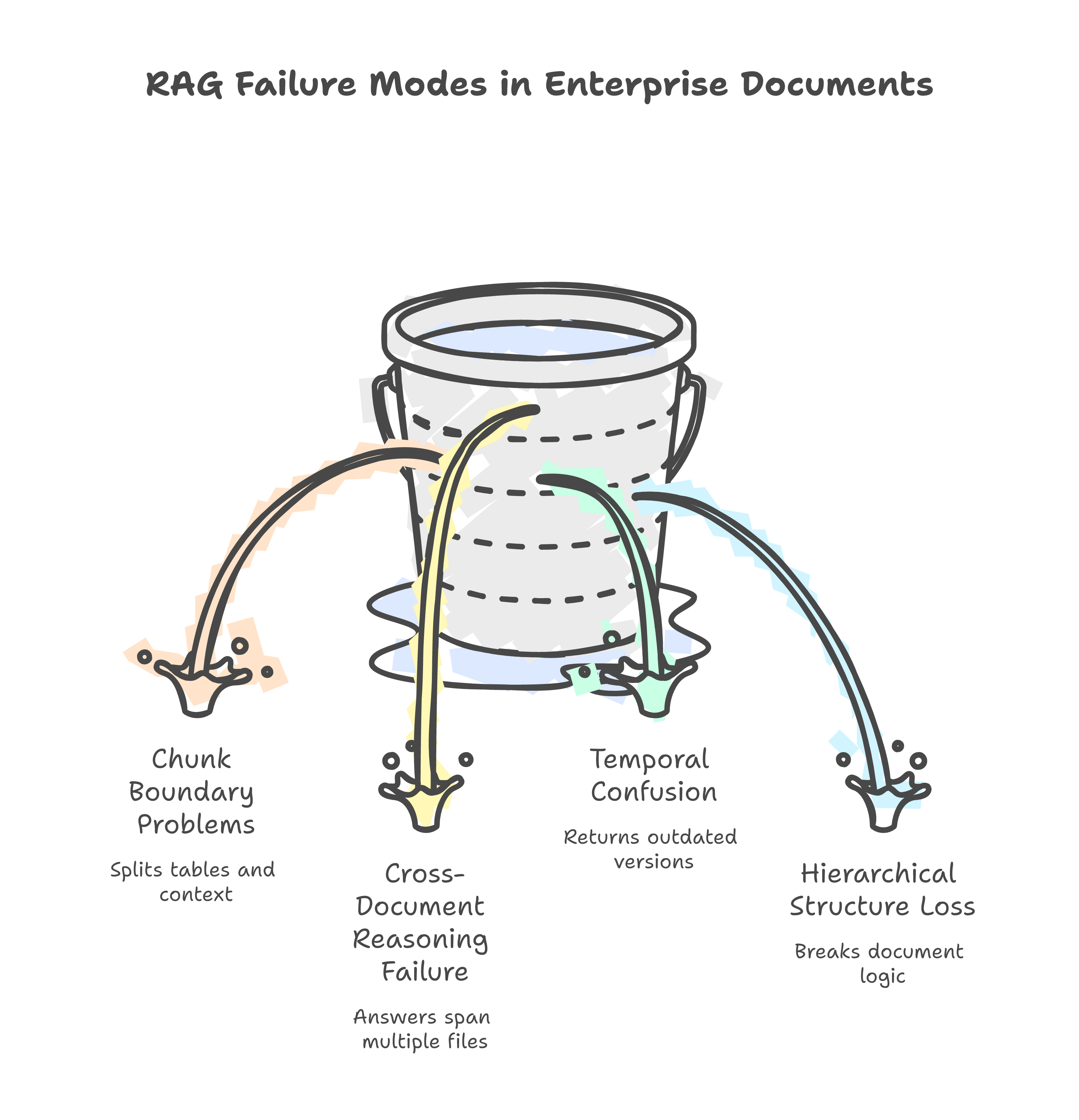
Failure Mode 1: Cross-Reference Blindness
Enterprise documents are full of cross-references. "As described in Section 3.2," "per the guidelines in Appendix B," "subject to the conditions in Clause 7." Basic RAG retrieves chunks independently. It has no concept of following a reference from one part of the document to another.
When you chunk a 50-page document into 512-token segments, you shatter these cross-references. The chunk containing "subject to conditions in Clause 7" and the chunk containing the actual conditions in Clause 7 are retrieved independently, if they are retrieved at all.
Failure Mode 2: Contextual Qualifiers Get Lost
Legal and regulatory documents are precision instruments. The difference between "shall" and "should," between "requirement" and "recommendation," between "must comply by" and "should target" -- these distinctions matter enormously. But a chunk that contains "KYC process upgrade" and "Q3" will score highly for the query "KYC upgrade deadline" regardless of whether the surrounding context says it is mandatory or optional.
Failure Mode 3: Tables and Structured Data
Basic RAG was designed for prose. Enterprise documents are full of tables, flowcharts, numbered lists with hierarchical structure, and formatted data that loses its meaning when linearized into text chunks. Try extracting the correct value from a multi-page table after it has been chunked into overlapping text segments. It is not reliable.
Failure Mode 4: Scanned and Handwritten Documents
A significant portion of enterprise documents in Southeast Asia are scanned PDFs, sometimes with handwritten annotations. OCR gets you part of the way, but OCR errors compound through the RAG pipeline. A misread "Q3" as "Q8" or a garbled table structure leads to confidently wrong answers.
The Dual-Mode Architecture
Dual-Mode Over Single Pipeline
Our system dynamically selects between two modes based on query complexity and document characteristics.
Mode 1: Passive RAG (Simple Queries)
For straightforward factual lookups -- "What is the effective date of this policy?", "Who signed this contract?", "What is the total amount in Section 5?" -- passive RAG works well. These queries have a single, localized answer that exists in a specific place in the document.
But even our passive RAG has significant improvements over a vanilla implementation:
Hierarchical chunking. Instead of fixed-size chunks, we parse documents into a hierarchy: document > sections > subsections > paragraphs. Each chunk retains metadata about its position in the hierarchy. When retrieving, we include parent context (the section heading and document title) with every chunk.
class HierarchicalChunk:
content: str
document_id: str
section_path: list[str] # e.g., ["Chapter 3", "Section 3.2", "Clause (a)"]
chunk_index: int
parent_summary: str # LLM-generated summary of parent section
sibling_count: int # how many chunks at this level
has_table: bool
has_cross_reference: bool
Cross-reference linking. During ingestion, we detect cross-references using pattern matching and resolve them into explicit links between chunks. When a chunk references "Clause 7," we attach the content of Clause 7 as supplementary context.
Confidence scoring. Every retrieval comes with a confidence score that reflects not just embedding similarity but also structural alignment (does the query ask about a section and the chunk is from that section?) and coverage (does the retrieved context contain all the entities mentioned in the query?).
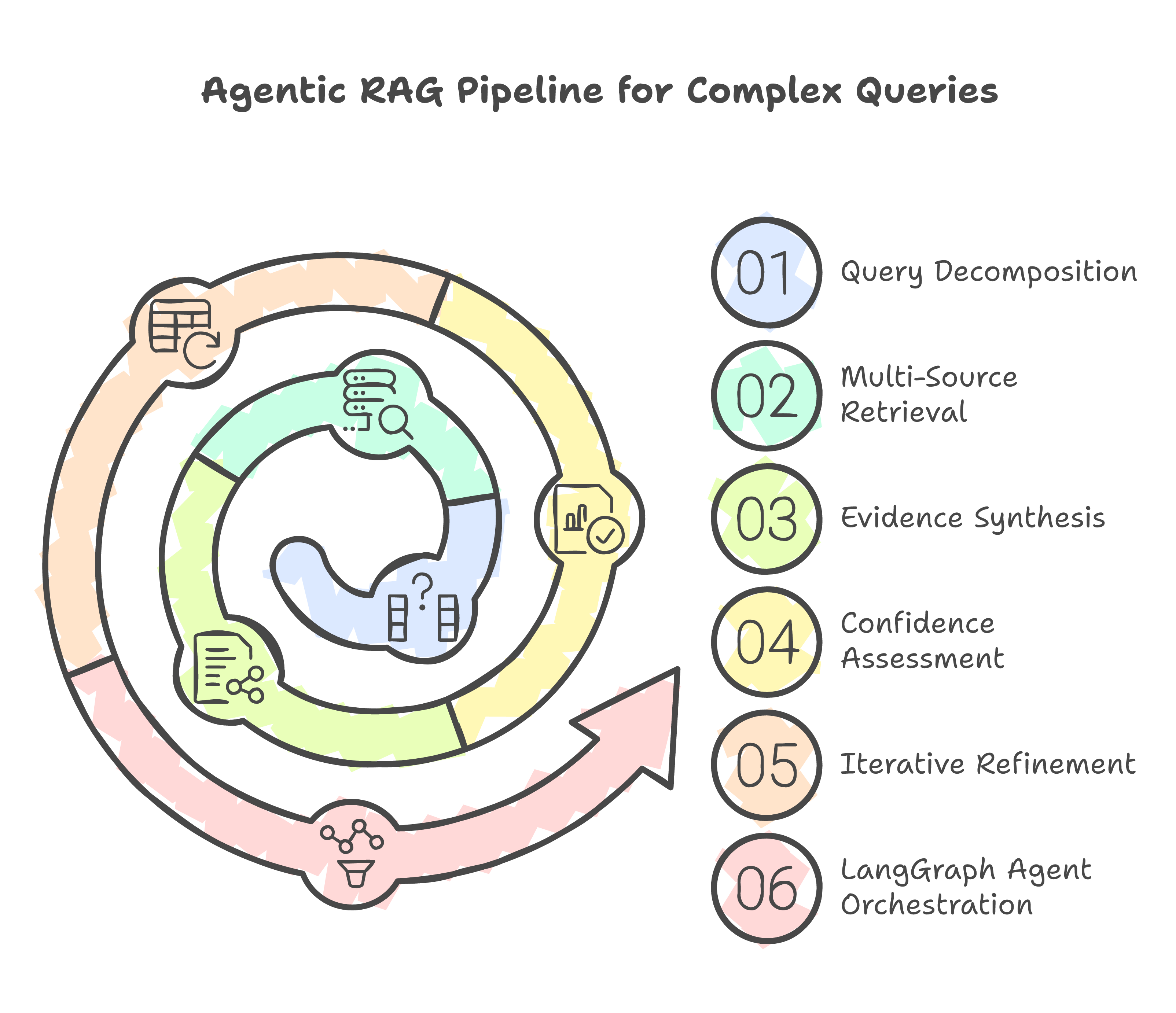
Mode 2: Agentic RAG (Complex Queries)
For queries that require reasoning across multiple sections, following cross-references, comparing information, or synthesizing conclusions, we switch to agentic mode. This is where LangGraph comes in.
The agentic RAG pipeline uses a multi-step process:
Step 1: Query Decomposition. The agent breaks the user's question into sub-questions. "Does this document require a KYC upgrade by Q3?" becomes:
- "What does this document say about KYC process upgrades?"
- "Is the KYC upgrade described as a requirement or a recommendation?"
- "What deadline is associated with the KYC upgrade?"
Step 2: Targeted Retrieval. Each sub-question triggers its own retrieval pass. This means the system searches for KYC-related content, compliance language (shall/should/must), and date/deadline mentions separately.
Step 3: Evidence Assembly. The agent collects the retrieved evidence for each sub-question and assembles it into a structured evidence document:
class EvidencePacket:
sub_question: str
retrieved_chunks: list[HierarchicalChunk]
extracted_answer: str
confidence: float
supporting_quotes: list[str] # exact quotes from the document
contradicting_evidence: list[str] # if any chunks disagree
Step 4: Synthesis with Citation. The agent generates a final answer that cites specific sections of the document. Every claim in the answer is traceable to a specific chunk and quote.
Step 5: Self-Verification. Before returning the answer, the agent runs a verification pass: does the synthesized answer actually follow from the evidence? Are there contradictions between sub-answers? Is the confidence level appropriate given the evidence quality?
class DocumentAgent:
async def answer(self, query: str, document_id: str) -> AgentResponse:
sub_questions = await self.decompose(query)
evidence_packets = []
for sq in sub_questions:
chunks = await self.retrieve(sq, document_id)
evidence = await self.extract_evidence(sq, chunks)
evidence_packets.append(evidence)
synthesis = await self.synthesize(query, evidence_packets)
verification = await self.verify(synthesis, evidence_packets)
if verification.has_contradictions:
synthesis = await self.resolve_contradictions(
synthesis, verification.contradictions
)
return AgentResponse(
answer=synthesis.text,
confidence=verification.overall_confidence,
citations=synthesis.citations,
evidence=evidence_packets,
)
Mode Selection: How the System Decides
The mode selector is a lightweight classifier that examines the query and document characteristics:
- Passive mode triggers: Single-entity queries, factual lookups, queries about a specific named section, queries with clear localized answers.
- Agentic mode triggers: Queries with temporal reasoning ("by when?"), comparative queries ("how does X compare to Y?"), conditional queries ("under what conditions?"), multi-section queries, queries requiring inference.
In practice, roughly 60% of queries go through passive mode and 40% through agentic mode. The classification itself adds negligible latency (~50ms) and prevents the system from using a sledgehammer for every nail.
VLM Integration for Scanned Documents
For documents that are scanned images or poorly-OCRed PDFs, we added a vision-language model (VLM) pipeline as a preprocessing stage.
Rather than attempting OCR and hoping for the best, we feed document pages directly to a VLM and ask it to extract structured content:
async def process_scanned_page(page_image: bytes, page_number: int) -> PageContent:
vlm_response = await vlm_client.analyze(
image=page_image,
prompt=(
"Extract all text content from this document page. "
"Preserve the document structure including: "
"- Headings and their hierarchy "
"- Table data in markdown table format "
"- List items with their numbering "
"- Any handwritten annotations "
"Return the content as structured markdown."
)
)
return PageContent(
page_number=page_number,
raw_text=vlm_response.text,
tables=vlm_response.extracted_tables,
confidence=vlm_response.confidence,
has_handwriting=vlm_response.detected_handwriting,
)
The VLM pipeline handles tables significantly better than traditional OCR because it understands spatial relationships. It can see that a number belongs in the third column of the second row, rather than treating the table as a sequence of disconnected text fragments.
For documents with mixed content (some pages are digital, some are scanned), we detect page type automatically and route accordingly. Digital pages go through direct text extraction. Scanned pages go through the VLM pipeline. The downstream RAG system receives consistent structured content regardless of the source format.
Confidence Scoring: Knowing What You Do Not Know
The most important feature of our system is not what it knows -- it is what it communicates about what it does not know.
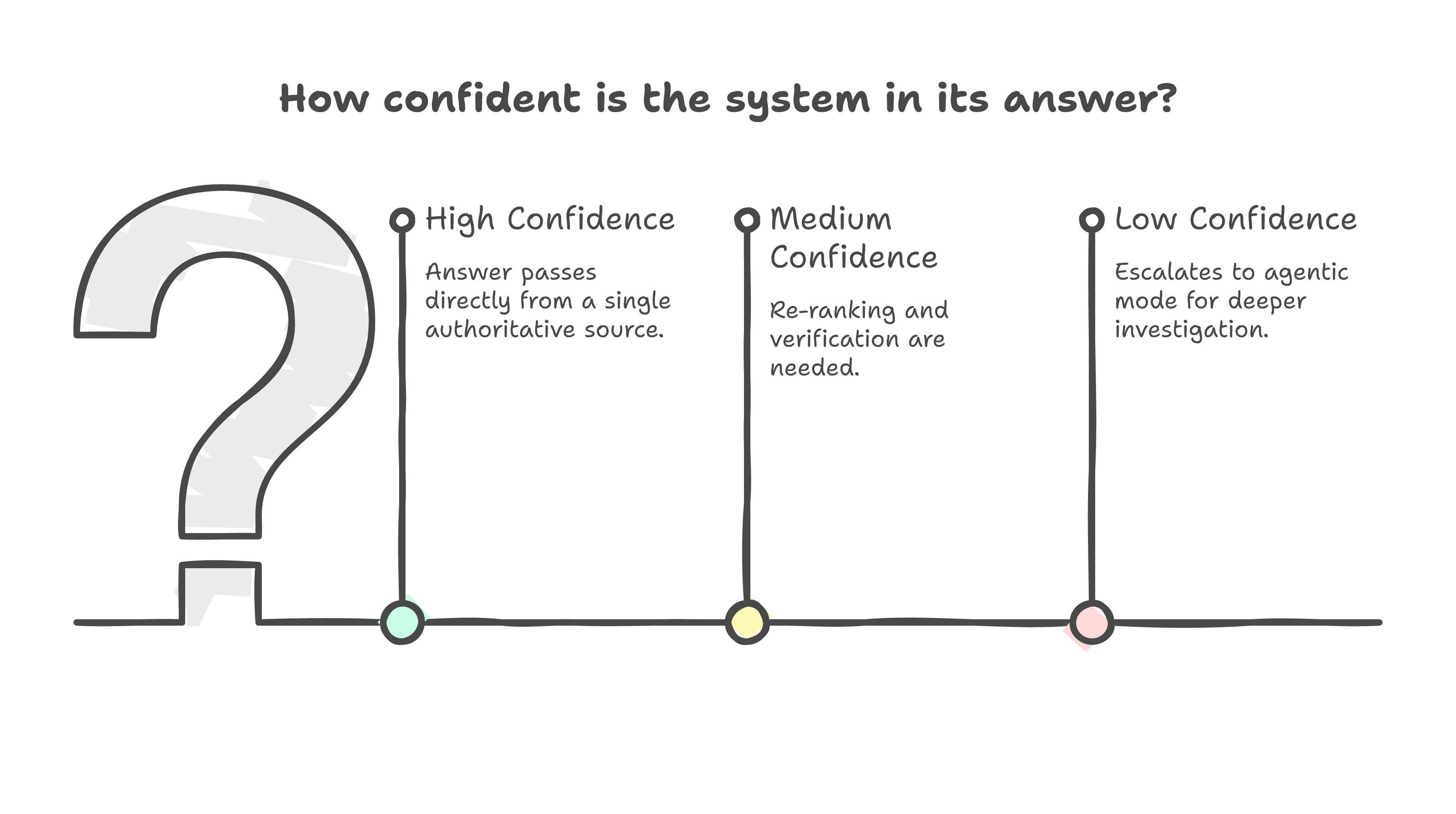
Every answer includes a confidence score on a 0-1 scale, with qualitative labels:
- 0.9-1.0 (High): Direct quote found, no ambiguity. "The effective date is January 1, 2026."
- 0.7-0.89 (Medium): Strong evidence but some inference required. "Based on Section 4.2, the deadline appears to be Q3 2026, though this is stated as a target rather than a firm deadline."
- 0.5-0.69 (Low): Partial evidence, significant inference. "The document mentions KYC improvements in two places but does not specify a clear deadline. The closest reference is..."
- Below 0.5 (Insufficient): The system explicitly declines to answer. "I could not find sufficient evidence in this document to answer this question reliably."
The Power of Saying "I Do Not Know"
Results and Lessons
After deploying this system across several enterprise clients processing thousands of documents monthly:
Dual-Mode System Performance
- Accuracy on complex queries improved from ~67% (basic RAG) to ~91% (dual-mode system)
- False confidence rate (wrong answers with high confidence) dropped from ~15% to under 3%
- Median query latency for passive mode: ~1.5 seconds; agentic mode: ~8 seconds
- Client trust -- the hardest metric to quantify but the most important -- improved significantly once users saw the system admit uncertainty rather than fabricate confidence
RAG is a retrieval technique, not an intelligence technique.
The core lesson: For enterprise use cases where accuracy has legal or financial consequences, you need to layer reasoning, verification, and honest uncertainty communication on top of retrieval. The documents are too important, and the stakes too high, for anything less.
If you are building document AI systems and facing similar challenges, I would welcome the conversation. This is a space where practical experience matters more than benchmarks.